
MLCommons Releases MLPerf Training v6.0 Results
SAN FRANCISCO, June 16, 2026 (GLOBE NEWSWIRE) — Right now, MLCommons® introduced new outcomes for the MLPerf® Coaching v6.0 benchmark suite. The 2 new benchmarks added on this spherical, and the submissions acquired, spotlight fast and vital modifications within the AI ecosystem.
“It’s an thrilling second for the group,” mentioned Shriya Rishab, MLPerf Coaching Working Group co-chair. “We’re seeing robust convergence on a set of greatest practices for coaching AI fashions, however on the identical time there’s growing technical variety within the underlying frameworks and programs which are getting used to host and run them.”
MLPerf Coaching v6.0 provides two new benchmarks, emphasizing sparse computation
The MLPerf Coaching benchmark suite includes full system checks that stress fashions, software program, and {hardware} for a spread of machine studying (ML) functions. The open-source and peer-reviewed benchmark suite supplies a stage enjoying area for competitors, driving innovation, efficiency, and vitality effectivity throughout the {industry}. The suite’s benchmark assortment is curated by a panel of specialists from the AI group.
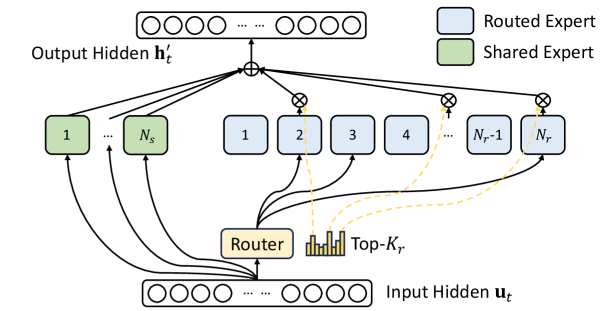
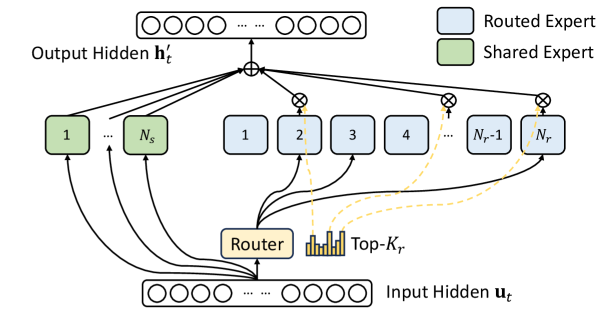
Model 6.0 provides two new benchmarks: DeepSeek V3 and GPT-OSS 20B, each highlighting the industry-wide shift to sparse computation as exemplified by a Combination-of-Specialists (MoE) structure. Combination-of-Specialists is a mannequin structure that makes use of a wise “router” to ship totally different tokens to specialised sub-networks (“specialists”). This permits utilizing a high-parameter-count mannequin that could be very environment friendly as a result of coaching and inference solely activate a fraction of the specialists for any given token, lowering the computational price.
DeepSeek V3 is a large-scale pretraining mannequin, using an MoE structure. It makes use of 671 billion complete parameters, of which 37 billion are activated per token. It supplies a standardized platform for evaluating the coaching effectivity of a number one open-weights MoE mannequin at manufacturing scale.
GPT-OSS 20B, additionally an MoE mannequin, makes use of a a lot smaller footprint: 21 billion complete parameters, of which 3.6 billion are activated per token. This permits organizations to guage the advanced routing logic and sparse computation patterns frequent to MoE structure on {hardware} configurations as small as a single 8-GPU node.
“Sparse computation is a dominant pattern in AI proper now,” mentioned Rishab. “Over the previous two years, the entire main new generative AI fashions have utilized a sparse computation structure, steadily MoE. We have now launched our new DeepSeek V3 benchmark to check large-scale sparse computation coaching programs, and actually it’s now the most important benchmark in our suite with 671 billion parameters. It additionally workouts the efficiency of vital improvements that at the moment are customary within the {industry}, together with Multi-head Latent Consideration (MLA) and auxiliary-loss-free load balancing.
“On the alternative finish of the spectrum, we’ve launched the GPT-OSS 20B benchmark as an entry level for organizations that won’t have the sources to coach the largest-scale fashions, however need to construct superior capabilities. We’ve fastidiously designed the benchmark for this situation, together with coaching from randomized weights to keep away from the overhead of multi-gigabyte checkpoint downloads; utilizing the identical dataset as present benchmarks within the suite comparable to Llama 3.1 8B; and selecting a consultant sliver of end-to-end coaching to scale back the price of producing benchmark outcomes with out compromising on the standard of the benchmark.
“Each of those new benchmarks noticed fast uptake, drawing many outcomes. Stakeholders clearly see the significance of efficiency benchmarking for MoE architectures.”
Rising variety of submissions highlights new paths to AI coaching
Model 6.0 set new information for variety of the programs submitted. Contributors on this spherical of the benchmark submitted 95 distinctive programs, using 13 totally different {hardware} accelerators, 19 totally different host processors and a few totally different software program frameworks. 60% of the programs have been multi-node.
Notably, there are greater than double the variety of cloud programs submitted in comparison with the model 5.1 outcomes six months in the past, reflecting the rising marketplace for internet hosting AI coaching within the cloud.
“There are extra methods of getting your AI coaching than ever earlier than,” mentioned Pavan Yalamanchili, MLPerf Working Group co-chair. “A number of firms now supply coaching programs within the cloud, complementing the on-premises programs that proceed to be constructed out at a livid tempo. And we’re excited to see so many aggressive submissions from quite a lot of on-premises and cloud suppliers.”
On the identical time, the submissions illustrate rising technical variety, reflecting a strong, quickly advancing ecosystem. For instance, submitters used a number of totally different FP4-precision recipes, reflecting the present variety and exploration throughout the {industry}.
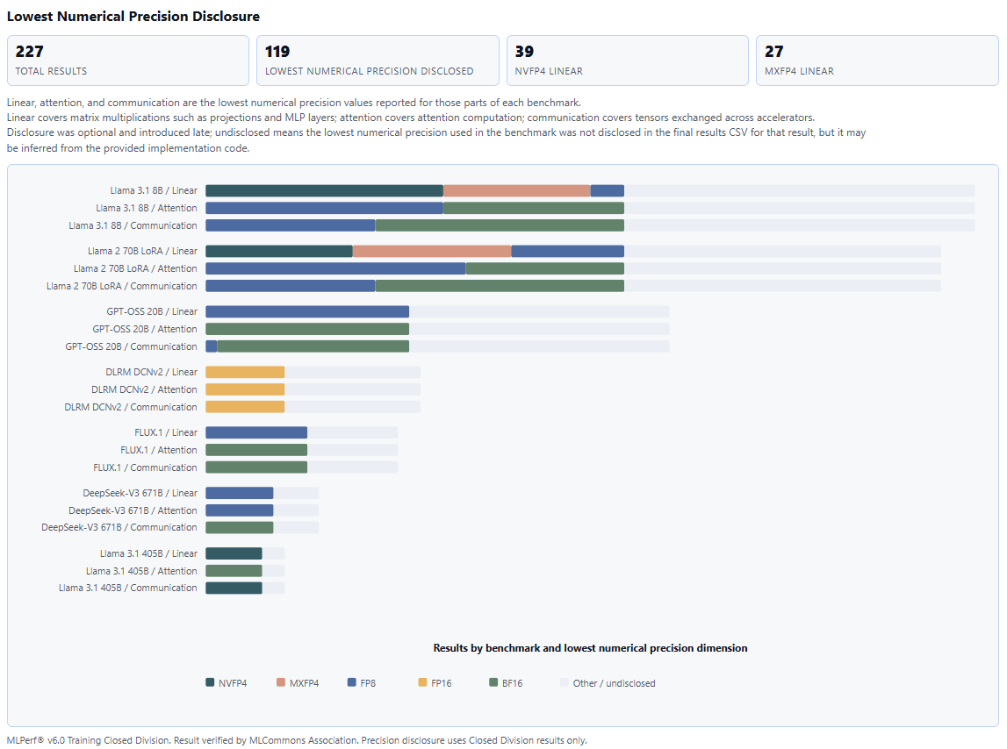
“The variety of FP4 implementations we see within the submissions is no surprise,” mentioned Yalamanchili. “Some implementations are extra versatile than others, which permit them for use in distinctive coaching eventualities. However right here is the place MLPerf’s benchmarking delivers vital perception and worth: it permits stakeholders to know which implementations ship the perfect efficiency for his or her particular wants. Specifically, as a result of MLPerf benchmarks require submissions to satisfy an accuracy threshold, we shine a highlight on the variations in efficiency that these sorts of {hardware} and implementation design selections can result in.”
Report {industry} participation factors to broad ecosystem, pushed by generative AI
The MLPerf Coaching v6.0 spherical consists of efficiency outcomes from 24 submitting organizations: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Neblus, Netweb Applied sciences India LTD, NVIDIA, Oracle, Quanta Cloud Applied sciences, SCITIX, Sigmicro, tinycorp, TTA and Vultr. “We’d particularly prefer to welcome first-time MLPerf Coaching submitters,” mentioned David Kanter, Head of MLPerf at MLCommons.
Strong participation by a broad set of {industry} stakeholders strengthens the AI ecosystem as a complete and helps to make sure that the benchmark is serving the group’s wants. We invite submitters and different stakeholders to hitch the MLPerf Training working group and assist us proceed to evolve the benchmark.
View the outcomes
Please go to the Coaching benchmark web page to view the full results for MLPerf Training v6.0 and discover further details about the benchmarks. To study every submitters outcomes, read the supplemental.
About ML Commons
MLCommons is the world’s chief in AI benchmarking. An open engineering consortium supported by over 125 members and associates, MLCommons has a confirmed document of bringing collectively academia, {industry}, and civil society to measure and enhance AI. The inspiration for MLCommons started with the MLPerf benchmarks in 2018, which quickly scaled as a set of {industry} metrics to measure machine studying efficiency and promote transparency of machine studying methods. Since then, MLCommons has continued utilizing collective engineering to construct the benchmarks and metrics required for higher AI – finally serving to to guage and enhance AI applied sciences’ accuracy, security, velocity, and effectivity.
For extra data on MLCommons and particulars on turning into a member, please go to MLCommons.org or e mail participation@mlcommons.org.
Press Inquiries: contact press@mlcommons.org
Photographs accompanying this announcement can be found at
https://www.globenewswire.com/NewsRoom/AttachmentNg/6c2628f4-74d8-4359-8ccd-f56a1a726c59
https://www.globenewswire.com/NewsRoom/AttachmentNg/2130345e-d371-43ec-8516-f9492165823d


