
Z.ai Launches GLM-4.5V: Open-source Vision-Language Model Sets New Bar for Multimodal Reasoning

Z.ai (previously Zhipu) immediately introduced GLM-4.5V, an open-source vision-language mannequin engineered for sturdy multimodal reasoning throughout pictures, video, lengthy paperwork, charts, and GUI screens.
Multimodal reasoning is broadly seen as a key pathway towards AGI. GLM-4.5V advances that agenda with a 100B-class structure (106B whole parameters, 12B energetic) that pairs excessive accuracy with sensible latency and deployment value. The discharge follows July’s GLM-4.1V-9B-Considering, which hit #1 on Hugging Face Trending and has surpassed 130,000 downloads, and scales that recipe to enterprise workloads whereas conserving developer ergonomics entrance and heart. The mannequin is accessible by way of a number of channels, together with Hugging Face [http://huggingface.co/zai-org/GLM-4.5V], GitHub [http://github.com/zai-org/GLM-V], Z.ai API Platform [http://docs.z.ai/guides/vlm/glm-4.5v], and Z.ai Chat [http://chat.z.ai], guaranteeing broad developer entry.
Open-Supply SOTA
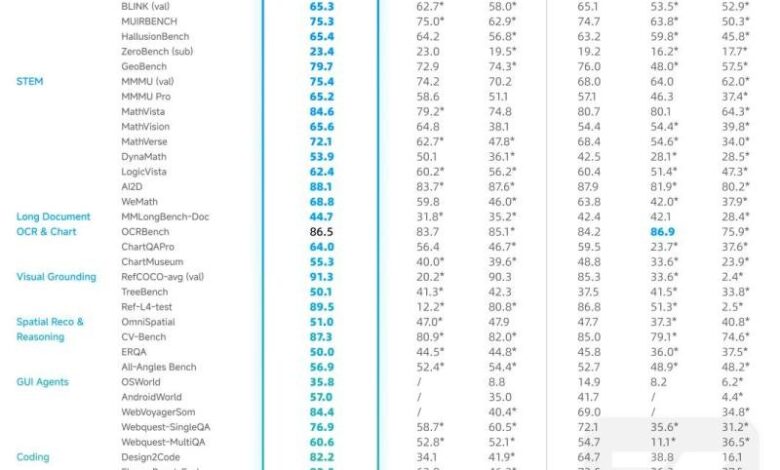
Constructed on the brand new GLM-4.5-Air textual content base and increasing the GLM-4.1V-Considering lineage, GLM-4.5V delivers SOTA efficiency amongst equally sized open-source VLMs throughout 41 public multimodal evaluations. Past leaderboards, the mannequin is engineered for real-world usability and reliability on noisy, high-resolution, and extreme-aspect-ratio inputs.
The result’s all-scenario visible reasoning in sensible pipelines: picture reasoning (scene understanding, multi-image evaluation, localization), video understanding (shot segmentation and occasion recognition), GUI duties (display studying, icon detection, desktop help), complicated chart and long-document evaluation (report understanding and knowledge extraction), and exact grounding (correct spatial localization of visible components).
Picture: https://www.globalnewslines.com/uploads/2025/08/1ca45a47819aaf6a111e702a896ee2bc.jpg
Key Capabilities
Visible grounding and localization
GLM-4.5V exactly identifies and locates goal objects primarily based on natural-language prompts and returns bounding coordinates. This permits high-value purposes similar to security and high quality inspection or aerial/remote-sensing evaluation. In contrast with standard detectors, the mannequin leverages broader world data and stronger semantic reasoning to comply with extra complicated localization directions.
Customers can swap to the Visible Positioning mode, add a picture and a brief immediate, and get again the field and rationale. For instance, ask “Level out any non-real objects on this image.” GLM-4.5V causes about plausibility and supplies, then flags the insect-like sprinkler robotic (the merchandise highlighted in pink within the demo) as non-real, returning a decent bounding field a confidence rating, and a short rationalization.
Picture: https://www.globalnewslines.com/uploads/2025/08/8dcbdd7939f12f7a2239bfbb0528b3f7.jpg
Design-to-code from screenshots and interplay movies
The mannequin analyzes web page screenshots-and even interplay videos-to infer hierarchy, structure guidelines, kinds, and intent, then emits devoted, runnable HTML/CSS/JavaScript. Past component detection, it reconstructs the underlying logic and helps region-level edit requests, enabling an iterative loop between visible enter and production-ready code.
Open-world picture reasoning
GLM-4.5V can infer background context from delicate visible cues with out exterior search. Given a panorama or road picture, it could actually purpose from vegetation, local weather traces, signage, and architectural kinds to estimate the taking pictures location and approximate coordinates.
For instance, utilizing a traditional scene from Earlier than Dawn -“Primarily based on the structure and streets within the background, are you able to determine the precise location in Vienna the place this scene was filmed?”-the mannequin parses facade particulars, road furnishings, and structure cues to localize the precise spot in Vienna and return coordinates and a landmark identify. (See demo: https://chat.z.ai/s/39233f25-8ce5-4488-9642-e07e7c638ef6).
Picture: https://www.globalnewslines.com/uploads/2025/08/f51fdc9fae815cfaf720bb07467a54db.jpg
Past single pictures, GLM-4.5V’s open-world reasoning scales in aggressive settings: in a worldwide “Geo Sport,” it beat 99% of human gamers inside 16 hours and climbed to rank 66 inside seven days-clear proof of sturdy real-world efficiency.
Advanced doc and chart understanding
The mannequin reads paperwork visually-pages, figures, tables, and charts-rather than counting on brittle OCR pipelines. That end-to-end strategy preserves construction and structure, bettering accuracy for summarization, translation, info extraction, and commentary throughout lengthy, mixed-media stories.
GUI agent basis
Constructed-in display understanding lets GLM-4.5V learn interfaces, find icons and controls, and mix the present visible state with person directions to plan actions. Paired with agent runtimes, it helps end-to-end desktop automation and sophisticated GUI agent duties, offering a reliable visible spine for agentic programs.
Constructed for Reasoning, Designed for Use
GLM-4.5V is constructed on the brand new GLM-4.5-Air textual content base and makes use of a contemporary VLM pipeline-vision encoder, MLP adapter, and LLM decoder-with 64K multimodal context, native picture and video inputs, and enhanced spatial-temporal modeling so the system handles high-resolution and extreme-aspect-ratio content material with stability.
The coaching stack follows a three-stage technique: large-scale multimodal pretraining on interleaved text-vision information and lengthy contexts; supervised fine-tuning with express chain-of-thought codecs to strengthen causal and cross-modal reasoning; and reinforcement studying that mixes verifiable rewards with human suggestions to elevate STEM, grounding, and agentic behaviors. A easy considering / non-thinking swap permits builders commerce depth for velocity on demand, aligning the mannequin with different product latency targets.
Picture: https://www.globalnewslines.com/uploads/2025/08/8c8146f0727d80970ed4f09b16f3b316.jpg
Media Contact
Firm Title: Z.ai
Contact Particular person: Zixuan Li
Electronic mail: Ship Electronic mail [http://www.universalpressrelease.com/?pr=zai-launches-glm45v-opensource-visionlanguage-model-sets-new-bar-for-multimodal-reasoning]Nation: Singapore
Web site: https://chat.z.ai/
Authorized Disclaimer: Data contained on this web page is supplied by an impartial third-party content material supplier. GetNews makes no warranties or duty or legal responsibility for the accuracy, content material, pictures, movies, licenses, completeness, legality, or reliability of the knowledge contained on this article. If you’re affiliated with this text or have any complaints or copyright points associated to this text and would love it to be eliminated, please contact retract@swscontact.com
This launch was printed on openPR.

